55:148 Digital Image Processing
55:247 Image Analysis and Understanding
Chapter 9,
3D Vision: 3D vision tasks
Chapter 9.1 Overview:
- 3D vision using intensity images as input is difficult.
- I:
- The imaging system of a camera and the human eye performs perspective projection, which
leads to considerable loss of information.
- All points along a line pointing from the optical center towards a scene point are
projected to a single image point.
- We are interested in the inverse task that aims to derive 3D co-ordinates from image
measurements - this task is underconstrained, and some additional information must be
added to solve it unambiguously.
- II:
- The relationship between image intensity and the 3D geometry of the corresponding scene
point is very complicated.
- The pixel intensity depends on surface reflectivity parameters, surface orientation,
type and position of illuminants, and the position of the viewer.
- Attempting to learn about 3D geometry, surfaces orientation and depth represents another
ill-conditioned task.
- III:
- The mutual occlusion of objects in the scene, and even self-occlusion of one object,
further complicates the vision task.
- IV:
- The field of 3D vision is young and still developing.
- No unified theory is available.
3D vision tasks
- Marr defines 3D vision as
- From an image (or a series of images) of a scene, derive an accurate three-dimensional
geometric description of the scene and quantitatively determine the properties of the
object in the scene
- 3D vision is formulated as a 3D object reconstruction task, i.e. description of the 3D
shape in a co-ordinate system independent of the viewer.
- One rigid object, whose separation from the background is straightforward, is assumed,
and the control of the process is strictly bottom-up from an intensity image through
intermediate representations.
- Wechsler stresses the control principle of the process:
- The visual system casts most visual tasks as minimization problems and solves them using
distributed computation and enforcing nonaccidental, natural constraints.
- Computer vision is seen as a parallel distributed representation, plus parallel
distributed processing, plus active perception.
- The understanding is carried in the perception - control - action.
- Aloimonos asks what principles might enable us to;
- (i) understand vision of living organisms,
- (ii) equip machines with visual capabilities.
- Aloimonos and Shulman see the central problem of computer vision as:
- ... from one or the sequence of images of a moving or stationary object or scene taken
by a monocular or polynocular moving or stationary observer, to understand the
object or the scene and its three-dimensional properties.
- System theory provides a general framework that allows us to treat understanding of
complex phenomena using the machinery of mathematics.
- The objects and their properties need to be characterized, and a formal mathematical
model is typically used for this abstraction.
- The model is specified by a relatively small number of parameters, which are typically
estimated from the (image) data (e.g. algebraic or differential equations).
- Some authors propose object recognition systems in which 3D models are avoided.
- The priming-based (geons) approach is based on the idea that 3D shapes can be inferred
directly from 2D drawings - the qualitative features are called geons.
- Constituents of a single object (geons) and their spatial arrangement are pointers to a
human memory and are used in the recognition process.
- The alignment of 2D views is another option - lines or points in 2D views can be
used for aligning different 2D views.
- The correspondence of points, lines or other features must be solved first. A linear
combination of views has been used for recognition., and various issues related to image
based scene representations in which a collection of images with established
correspondences is stored instead of a 3D model.
Marr's theory
- Marr was critical of earlier work that, while successful in limited domains or image
classes, was either empirical or unduly restrictive of the images with which it could
deal.
- Marr proposed a more abstract and theoretical approach that permitted work to be put
into a larger context.
- Marr's work was restricted to 3D interpretation of single, static scenes.
- Marr proposed three levels:
- Computational theory:
- describes what the device is supposed to do; what information it provides from other
information provided as input. It should also describe the logic of the strategy that
performs this task.
- Representation and algorithm:
- address precisely how the computation may be carried out; including information
representations and algorithms to manipulate them.
- Implementation:
- includes physical realization of the algorithm; programs and hardware.
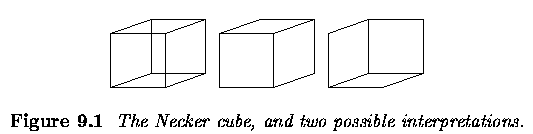
- Example ... an after-image (induced by staring at a light bulb) is a physical effect,
while the mental confusion provoked e.g., by the well known Necker cube is at a different
level.
- The primal sketch
- The primal sketch aims to capture, in as general a way as possible, the significant
intensity changes in an image.
- Such changes have been referred to as `edges' but Marr makes the observation that this
word implies a physical meaning that cannot at this stage be inferred.
- The first stage is to locate these changes at a range of scales after which second-order
zero crossings are determined for each scale of blur.
- Zero crossing evidence in the same locality at many scales provides strong evidence of a
genuine physical feature in the scene.
- Zero crossings are grouped, according to their location and orientations, to provide
information about tokens in the image (edges, bars and blobs) that may help provide later
information about (3D) orientation of scene surfaces.
- The grouping phase, paying attention to the evidence from various scales, extracts
tokens that are likely to represent surfaces in the real world.
- (There is strong evidence for the existence of the various components used to build the
primal sketch in the human visual system - we too engage in detection of features at
various scales, the location of sharp intensity changes and their subsequent grouping into
tokens.)
- The 2.5D sketch
- The 2.5D sketch reconstructs the relative distances from the viewer of surfaces detected
in the scene, and may be called a depth map.
- The output of this phase uses as input features detected in the preceeding phase.
- It does not provide a 3D reconstruction.
- It is midway between 2D and 3D representations.
- 3D representation
- Marr paradigm overlaps with top-down, model-based approaches.
- This step represents a transition to an object centered co-ordinate system, allowing
object descriptions to be viewer independent.
- This is the most difficult phase and successful implementation is remote, especially
compared to the success seen with the derivation of the primal and 2.5D sketches.
- The Marr paradigm advocates a set of relatively independent modules; the low-level
modules aim to recover a meaningful description of the input intensity image, the
middle-level modules use different cues such as intensity changes, contours, texture,
motion to recover shape or location in space.
- The Marr paradigm is a nice theoretic framework, but unfortunately does not lead to
successful vision applications performing, e.g., recognition and navigation tasks.
- It was shown later that most low-level and middle-level tasks are ill-posed, with no
unique solution.
- One popular way developed in the eighties to make the task well-posed is regularization.
A constraint requiring continuity and smoothness of the solution is often added.
Other vision paradigms: Active and purposive
vision
- When consistent geometric information has to be explicitly modeled (as for manipulation
of the object), an object-centered co-ordinate system seems to be appropriate.
- Two schools are trying to explain the vision mechanism:
- The first and older one tries to use explicit metric information in the early stages of
the visual task (lines, curvatures, normals, etc.).
- Geometry is typically extracted in a bottom-up fashion without any information about the
purpose of this representation.
- The output is a geometric model.
- The second and younger school does not extract metric (geometric) information from
visual data until needed for a specific task.
- Data are collected in a systematic way to ensure all the object's features are present
in the data, but may remain uninterpreted until a specific task is involved.
- A database or collection of intrinsic images (or views) is the model.
- Many traditional computer vision systems and theories capture data with cameras with
fixed characteristics while active perception and purposive vision may be
appropriate.
- Active vision system ... characteristics of the data acquisition are dynamically
controlled by the scene interpretation.
- Many visual tasks tend to be simpler if the observer is active and controls its visual
sensors.
- The controlled eye (or camera) movement is an example.
- If there is not enough data to interpret the scene the camera can look at it from other
viewpoint.
- Active vision is an intelligent data acquisition controlled by the measured, partially
interpreted scene parameters and their errors from the scene.
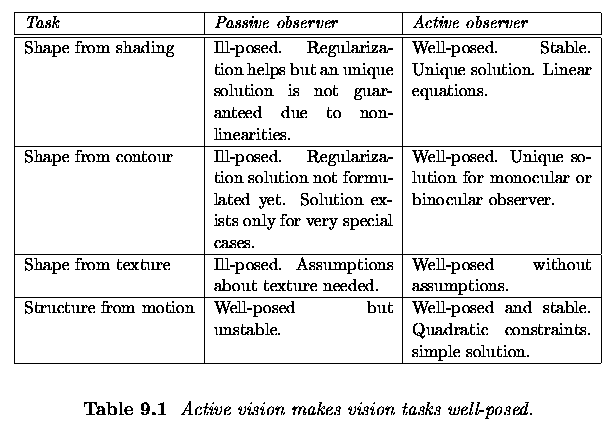
The active approach can make most ill-posed vision tasks tractable.
- There is no established theory that provides a mathematical (computational) model
explaining the understanding aspects of human vision.
- Two recent developments towards new vision theory are:
- Qualitative vision
- that looks for a qualitative description of objects or scenes.
- The motivation is not to represent geometry that is not needed for qualitative
(non-geometric) tasks or decisions.
- Qualitative information is more invariant to various unwanted transformations (e.g.
slightly differing viewpoints) or noise than quantitative ones.
- Qualitativeness (or invariance) enables interpretation of observed events at several
levels of complexity.
- Purposive paradigm
- The key question is to identify the goal of the task, the motivation being to ease the
task by making explicit just that piece of information that is needed.
- Collision avoidance for autonomous vehicle navigation is an example where precise shape
description is not needed.
- The approach may be heterogeneous and a qualitative answer may be sufficient in some
cases.
- The paradigm does not yet have a solid theoretical basis, but the study of biological
vision is a rich source of inspiration.
Last Modified: April 20, 1997
![[Go Back]](../IMAGES/next.gif)